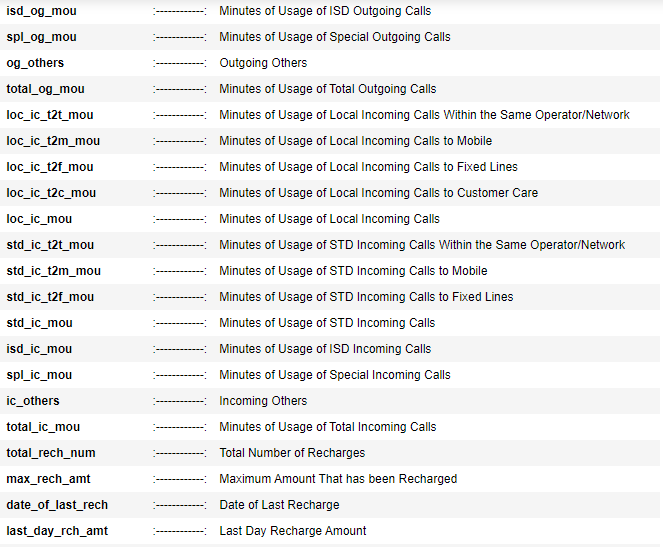
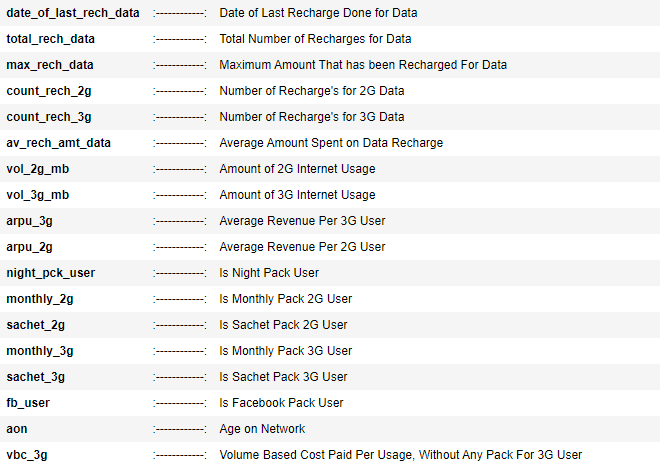
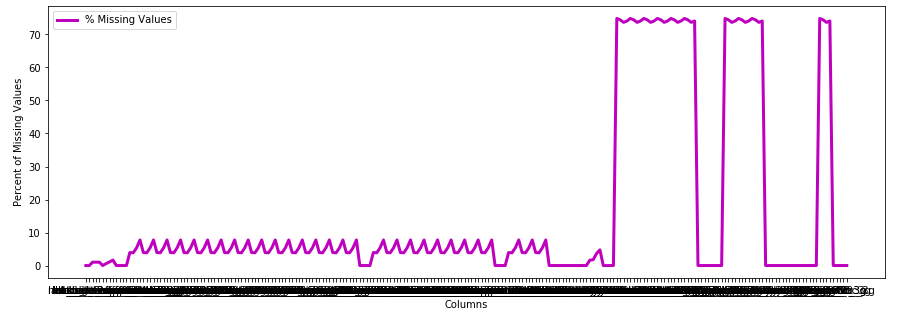
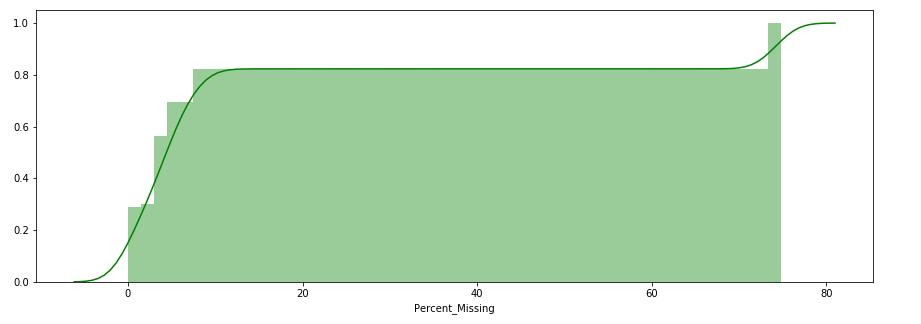
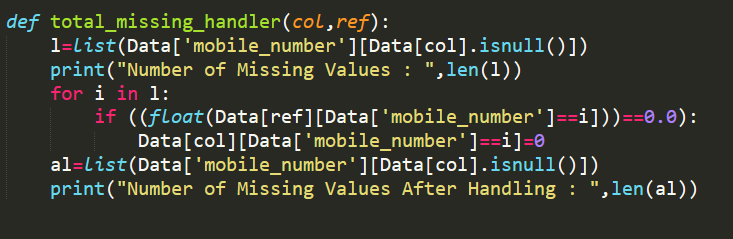
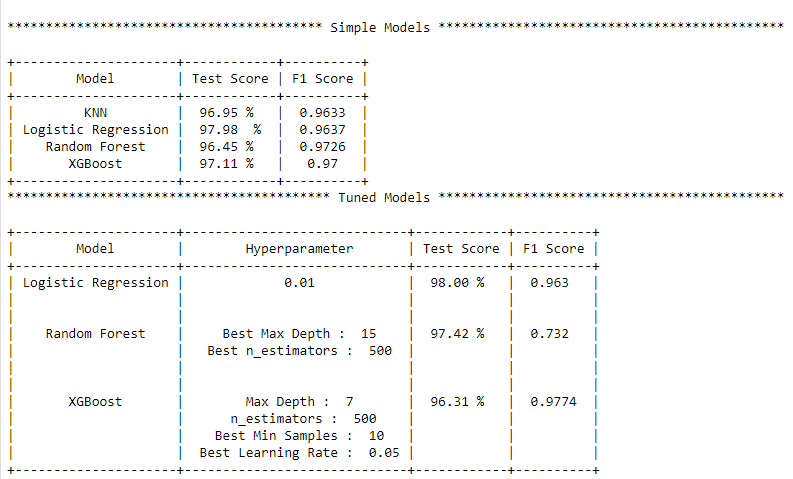
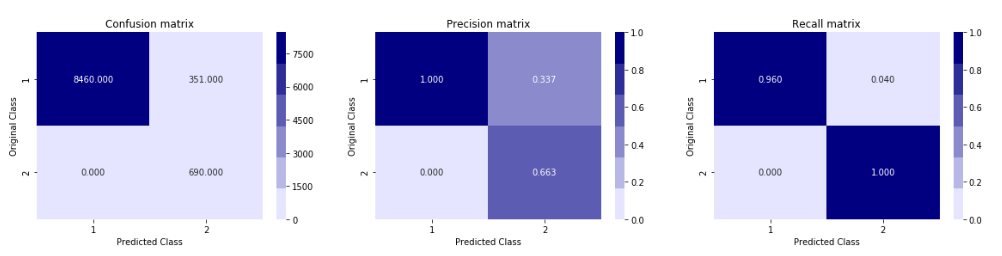
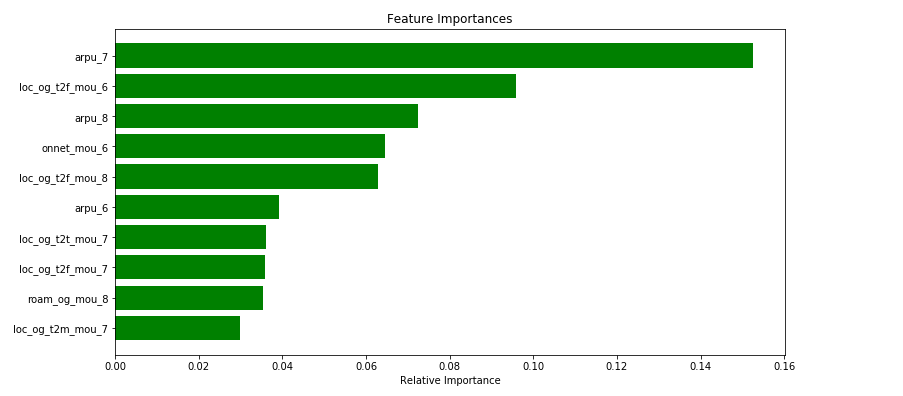
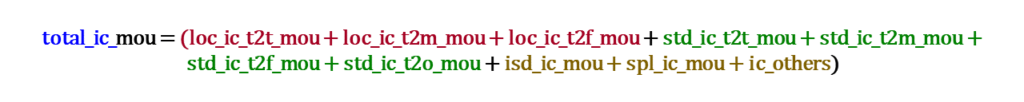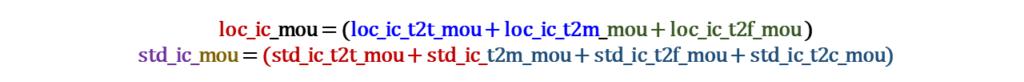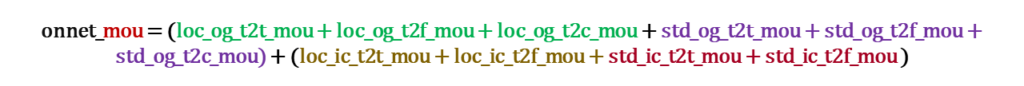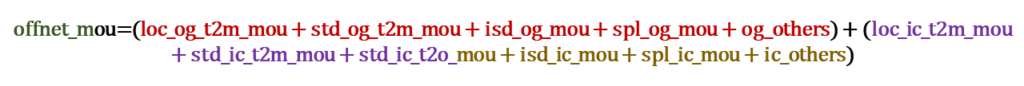Customer Value Segmentation :
Segmenting Customers by Value, the Standard Approach used is the ‘Decile Analysis’. This Calculates a Value Measure for each Customer, sorts the Customer Base into Descending Order by Value and then Splits the Base into 10 Equal Segments. The First or Top Decile is the Top 10 Percent of the Base. The Second Decile is the next 10 per cent, and so on.
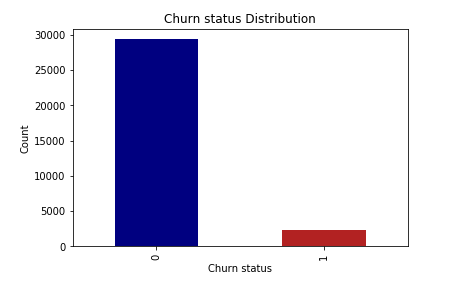
- Depending on the Decile Analysis of the Revenue Being Generated by the Customers in the Months of June and July.
- These are the Customer’s, who contribute Maximum Revenue to the Company.
- Identifying, these Customers with High Risk of Getting into Churn, can help the Company.
We are here considering, top 3 Deciles for segregating, as these customer’s are contributing more than 70% of revenue to the Company.