Building Input Data Pipeline using tf.data
In the traditional methods, most of the processing is done by CPU, Heavy Lifting is done by the GPU and both CPU and GPU have to wait till the next batch is fed. Thus, this makes these methods Inefficient One!
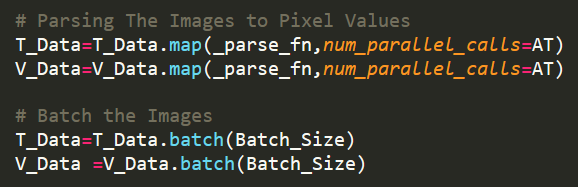
To overcome this Tensorflow provides tf.data API to build the Efficient and Scalable Input Pipelines. This could be the somewhat painful process for the first time, but the most efficient pipelines can be built using Tensorflow’s Dataset Module i.e. tf.data. This API from Tensorflow allows us to build Highly Optimized Pipelines both for text and image data, using the resources from GPU efficiently by feeding the Data continuously by dividing it into batches.
Let us understand tf.data by mapping it to the ETL Process i.e. Extract Transform and Load.
Extract Stage:
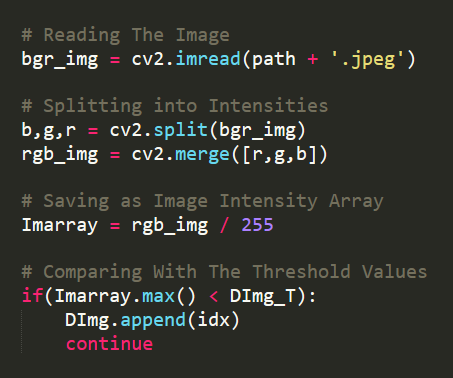
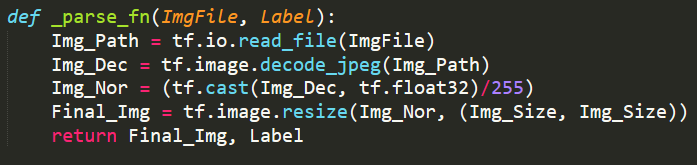
It is the phase of reading the data from a network storage or the local disk. In our case it is the Local Storage. So, the first step in this Pipeline is to create the dataset from the slices of File Names or Path’s.